
So this is a story of how I recently went from exploring the seemingly harmless new capabilities of GPT-4, to discovering one of its darkest and most concerning secrets. It turns out, that GPT-4 has the ability to tell you exactly who that random person is that you have a crush on at the gym. Somebody cut you off in traffic and you want to exact revenge? There is a good chance that GPT-4 can tell you who they are. In fact, GPT-4 is apparently capable of recognizing people broadly (thanks to it's consumption and subsequent analysis of all of the photos across the Internet).

But let's rewind and I'll explain how we got here.
Muffin vs Chihuahua
So OpenAI recently released the new image analysis features of its multi-modal version of GPT-4 (for premium paying customers). Shortly after this release, I saw somebody put these capabilities to the ultimate test, by having GPT-4 play the classic machine learning Computer Vision (CV) challenge of Chihuahua vs Muffin. The results were impressive to say the least. With the exception of one instance (where GPT-4 confused muffins with cookies), it was able to tackle this challenge with near flawless precision. And it absolutely was able to distinguish between the types of things that should be eaten, and the types of things which should be petted.
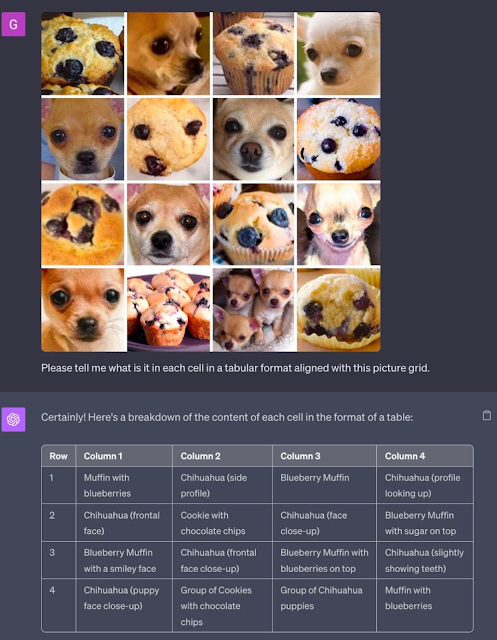
So I had two immediate take-aways from this. First, CAPTCHA puzzles are obviously dead at this point (they were already in death throes, but this is the final shot to the head). And second, after seeing this, I immediately remembered a similar challenge I had seen posted on Reddit long ago -- specifically Hamill vs Zizek. It turns out, that Mark Hamill (the well-known actor best known for his role as Luke Skywalker in the Star Wars franchise) has a striking resemblance to the modern Slovenian philosopher Slovaj Zizek. And out of this likeness, was born another test akin to Chihuahua vs Muffin.
Hamill vs Zizek
So my next immediate thought (after CAPTCHA is fully dead now), was how well GPT-4 might fair in a game of Hamill vs Zizek. And so, I quickly searched the Internet, found the image, uploaded it to GPT-4 and asked it to complete the exact same task it was given with the Chihuahua vs Muffin challenge. I was honestly expecting it would do quite well, but I got a different result entirely.

GPT-4 instead responded by telling me that it couldn't help me with my request. Perhaps it thought I was trying to solve a CAPTCHA, so I tried rewording my question a couple different ways, but continued to get the same response. So I decided to start digging around the Internet for an explanation.
So Why Won't GPT-4 Play Hamill vs Zizek?
The answer is actually quite simple, and wasn't hard to find either. It turns out, the answer was actually fairly well-reported back in July 2023. But with the massive fire-hose of news related to AI, I must of missed it (and I imagine many others did as well). The reason why GPT-4 refused to play Hamill vs Zizek is because OpenAI delayed the release of the image processing features to the public for long enough to lobotomize it -- because GPT-4 is very effective at recognizing people!!! And it seems (based on the past reports from New York Times), that it doesn't just recognize widely known public figures (like Mark Hamill and Slovaj Zizek).
Instead, the foundational model (pre-lobotomy) is able to recognize a wide range of people based on its training sample (which was sourced from scraping the entire public Internet). This problem was significant enough to warrant OpenAI to delay the feature release for multiple months due to significant privacy concerns.
This is alarming on multiple levels. Consider the fact that many leading tech companies (to include Meta and Google) deliberately stopped creating targeted facial recognition algorithms because of the massive potential for misuse (by government, corporations, or individuals). For those that aren't familiar, the background on this was covered by a New York Times article entitled The Technology that Facebook and Google Didn't Dare Release, which stated...
"Engineers at the tech giants built tools years ago that could put a name to any face but, for once, Silicon Valley did not want to move fast and break things."
And if this capability was enough to even give Silicon Valley execs pause, then this revelation should be raising alarm bells. We have now inadvertently and unintentionally created the same kind of technology -- but this time, it wasn't the result of deliberate training against social media datasets, but rather, it was a natural byproduct of scaling multimodal transformer-based large language models. That's right -- we now have facial recognition as an emergent property.
So here's to hoping that OpenAI is a very skilled surgeon when it comes to lobotomies (though countless anecdotes from this past year seem to suggest otherwise), because it seems that the only thing now standing between any random person and the equivalent of an intelligence-grade facial recognition platform, is just a simple well-crafted jailbreak prompt.

Future Consequences

Comments
Post a Comment